Building Your Own AI Blog Generator on the Cloud: A Step-by-Step Adventure with AWS
A comprehensive demonstration of building an end-to-end generative AI application on the AWS cloud platform. Architecture involving API Gateway, Lambda functions, Amazon Bedrock, and S3 storage to generate blogs based on user queries.
@AI
Ankit Kumar Tiwari
5/6/20257 min read
The Grand Plan: How Our Blog Generator Will Work
Before we dive into the nitty-gritty, let's get a bird's-eye view of how all the pieces fit together. Think of it like building with LEGOs – you need the right bricks and you need to know how they snap together.
Here’s the basic flow of our generative AI blog generator application:
The Starting Point (The Request): We’ll start by creating a way for someone to tell our application what blog topic they want. We’ll use something called an API (Application Programming Interface) for this. You can think of an API like a menu at a restaurant – it shows you what you can order and how to ask for it. We'll use a tool called Amazon API Gateway to create this menu.
The Waiter (The Trigger): When someone uses our API (like ordering from the menu using a tool called Postman), this action will trigger another part of our system.
The Kitchen Helper (The Code Runner): This trigger will tell a special service called AWS Lambda to run some code. Lambda is amazing because it lets you run code without having to worry about managing servers – AWS handles all that tricky stuff for you.
The Master Chef (The AI Brain): Inside our Lambda code, we'll tell it to talk to the real star of the show: the Amazon Bedrock service. This is where all the powerful Foundation Models (FMs) live. These FMs are the actual AI brains that can understand our blog topic and write the blog post.
The Recipe Output (The Generated Blog): Bedrock will process our request using one of its FMs and send back the generated blog post to our Lambda code.
The Storage Room (Saving the Output): Finally, our Lambda code will take the freshly generated blog post and save it for us. We’ll use Amazon S3 (Simple Storage Service), which is like a giant online storage locker for files. We'll save the blog as a text file, perhaps adding a timestamp to the filename so we know when it was created.
So, in simple terms: API Gateway takes the request -> Lambda runs the code -> Bedrock generates the blog -> S3 saves the blog.
This is a powerful way many companies build AI applications on AWS.
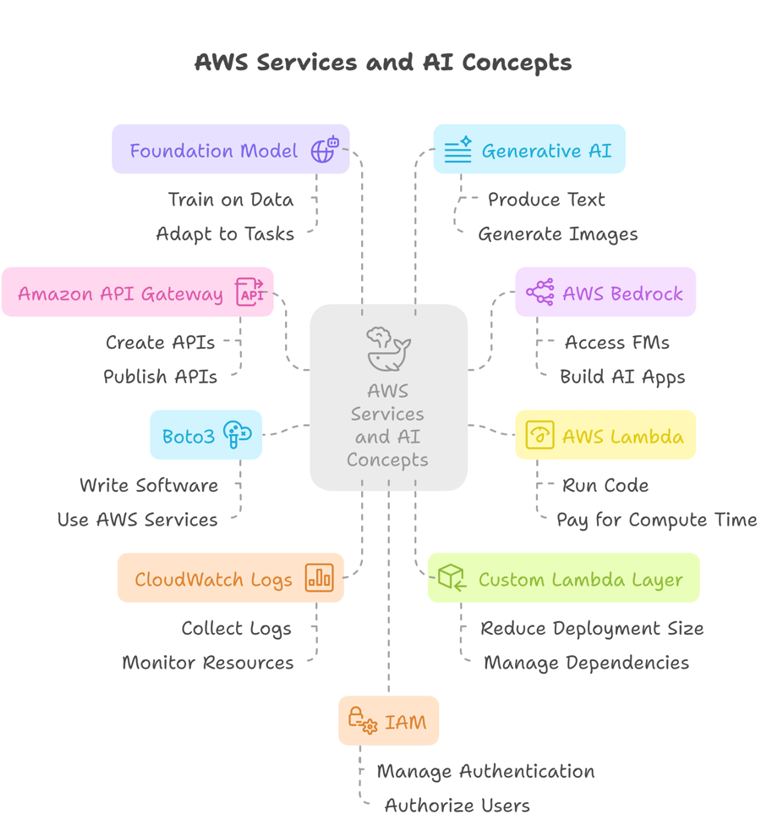
Meeting the AWS Team: Key Services We'll Use
Let's get to know the main services we'll be working with a little better.
Amazon Bedrock: This is your central hub for using powerful AI models built by different companies. Instead of setting up each model yourself, Bedrock gives you access to a variety of Foundation Models ready to go. You can find models from companies like AI21 Labs, Amazon itself, Anthropic (with their Claude models), Cohere, Meta (like Llama 2 and Llama 3), Mistral, and you can even generate images with models like Stable Diffusion. Using these models involves telling them what you want (this is called the "prompt") and sometimes setting other details like how long the answer should be or how creative it should be. Important: To use these models, you first need to request access to them within the Bedrock service. This is like getting permission to use specific tools.
AWS Lambda: This is a fantastic service for running your code. The best part? It's serverless. This means you don't have to worry about setting up, managing, or scaling servers. Lambda automatically handles everything for you. It runs your code only when needed (like when our API is triggered), scales up or down based on how many requests you get, and you only pay for the time your code is actually running. It's great for smaller tasks or applications.
Amazon API Gateway: This service acts as the front door for your application. It lets you create secure and scalable APIs that other applications or users can interact with. We'll use it to create a specific web address (a URL) that, when sent a request, will trigger our Lambda function.
Amazon S3: This is Amazon's popular service for storing files. It's highly durable and scalable, perfect for keeping our generated blog posts safe and accessible. We'll create a specific storage location called an S3 bucket to hold our blog files. Bucket names need to be unique across all of AWS.
Getting Your Hands Dirty: Setting Up and Coding
To start, you'll need an AWS account. Once you have that, the process generally involves these steps:
Get Bedrock Model Access: Go into the Bedrock service and request access to the Foundation Models you want to use, for example, the Meta Llama models.
Create Your Lambda Function: In the AWS Lambda service, you'll create a new function. You'll give it a name (like AWS-Bedrock-app) and choose a programming language runtime, like Python 3.12.
Write the Code: The core logic for our application lives inside this Lambda function. We'll write Python code using the boto3 library, which is the AWS SDK for Python, allowing our code to interact with other AWS services like Bedrock and S3.
The Blog Generation Logic: We'll have a function specifically for talking to Bedrock. This function will take the blog topic you provide. It will then create a "prompt" – the instruction for the AI model – formatted in a way the specific model (like Llama 2) understands. It will also include parameters like the max_gen_length (how long the blog should be, e.g., 200 words) and potentially temperature or top_p to control the creativity of the output. Using boto3, this function will call the Bedrock service, specifying which model to use (identified by its modelId) and sending the prompt and parameters. Bedrock sends back a response, and our code will extract the generated text from it.
The Main Handler: Lambda functions have a main entry point, usually called lambda_handler. This is the function that runs when API Gateway triggers our Lambda. This handler will receive the information sent by API Gateway, including the blog topic we provided in the request body. It will then call our blog generation function.
Saving to S3: We'll have another piece of code, maybe in a separate function, responsible for saving the generated blog to our S3 bucket. It will use boto3 to put the file into the specified bucket (S3 bucket name) with a chosen filename (S3 key), often including a timestamp.
Error Handling: Good code includes try...except blocks to catch errors if something goes wrong, like if the AI model can't be called. Any print statements in the Lambda code will show up in CloudWatch logs, which is super helpful for seeing what happened.
Handling Dependencies with Lambda Layers: Your Lambda function needs the right tools (software libraries) installed to run your code. By default, Lambda has some libraries, but you might need specific versions or additional ones (like an updated boto3 that knows how to talk to Bedrock). This is where Lambda Layers come in. You can create a layer by installing the required libraries into a specific folder structure (python/your_libraries), zipping that folder, and uploading it to AWS. You can then attach this layer to your Lambda function, giving your code access to those libraries. This is a common and very useful technique.
Deploy the Code and Layer: Once your code is written and packaged (including setting up your layers), you deploy it to your Lambda function.
Connecting Everything: API Gateway and S3
Create the S3 Bucket: Go to the S3 service and create a new bucket. Remember the name you chose in your code (like AWS-Bedrock-Bedrock-course-one). Bucket names are like website addresses – they must be globally unique.
Set up API Gateway: In the API Gateway service, create a new HTTP API. Give it a name.
Define the Route: Create a route for your API. This is the specific path users will hit, like /blog-generation. For our blog generator, this route will likely accept POST requests, as we are sending data (the blog topic) to create something new.
Integrate with Lambda: Connect this API Gateway route directly to your Lambda function. This tells API Gateway to send any requests it receives at that route to your Lambda code.
Deploy the API: Deploy your API Gateway setup to a stage, like a "Dev" (Development) stage. This makes your API accessible via a unique URL.
Testing and Troubleshooting
With everything set up, it's time to test!
Using Postman: You can use a tool like Postman to send a test POST request to the API Gateway URL you deployed. In the body of the request, you'll include the blog topic, typically in a JSON format like {"blog_topic": "Machine Learning and Generative AI"}.
Checking the Output: If everything works, you should get a response back from API Gateway, hopefully saying something like "Blog generation is completed" with a status code of 200 (which means success).
Looking at Logs: If you get an error, the CloudWatch logs for your Lambda function are your best friend. They show you exactly what happened when your code ran.
Permissions, Permissions, Permissions! A very common problem is that your Lambda function doesn't have the necessary permissions to talk to other AWS services. The error messages in CloudWatch will often tell you this, mentioning things like "is not authorized" or "invoke model action". You need to go to the IAM (Identity and Access Management) role that your Lambda function is using and add policies that allow it to perform actions like bedrock:InvokeModel and s3:PutObject. Once you update the role with the right permissions, try testing again!
Verify in S3: After a successful run, go to your S3 bucket. You should see a new folder (like blog_output) and inside it, a text file with a timestamped name, containing your generated blog post.
Conclusion: Your AI Blog Generator is Ready!
Congratulations! By following these steps, you've successfully built and deployed an end-to-end generative AI blog generation application on AWS. You've seen how Amazon API Gateway acts as the entry point, AWS Lambda runs your code serverlessly, Amazon Bedrock uses powerful AI models to create content, and Amazon S3 stores the final output. You also learned about essential concepts like Lambda Layers for managing dependencies and IAM permissions for securing your application.
This project is just the beginning. You can expand on this by making the blogs longer, using different models, adding formatting, or even integrating other services for more complex tasks like question answering over documents (which might involve Vector Databases). Building on the AWS Cloud provides a robust ecosystem for all sorts of exciting generative AI applications.
Keep experimenting and building! The world of generative AI on the cloud is vast and full of possibilities.
Start today and turn your creativity into cash :
mycloudneed is a cloud consulting and AI management company that helps businesses deploy, fine-tune, and scale custom large language models (LLMs) using AWS infrastructure. They specialize in hosting and training both open-source and proprietary models, offering secure API access, custom data training, and enterprise-grade monitoring. Their services are designed to be cost-effective, providing solutions that are up to 80% less expensive than traditional options like ChatGPT, while ensuring full control and customization for clients. By leveraging AWS services such as Lambda and API Gateway, mycloudneed enables businesses to own and manage their AI infrastructure efficiently.